如何用AI自动将培训视频翻译成捷克语并配音?
使用鬼手剪辑,仅需三步,让你的培训视频快速触达全球捷克语观众
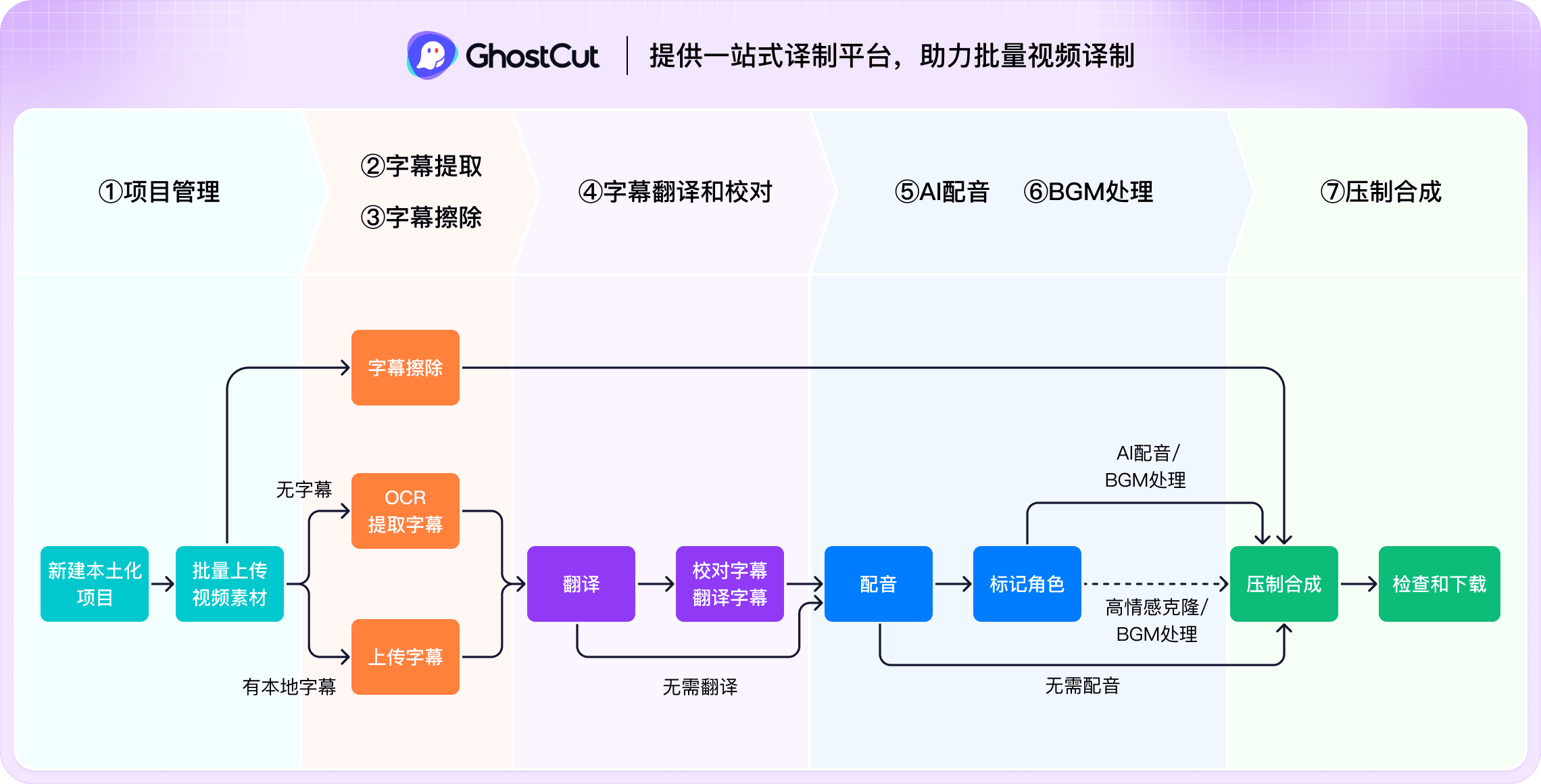
上传/粘贴培训视频
- 从设备批量上传MP4, MOV等培训视频文件。
- 或者,直接粘贴来自属于你自己的直接可访问的培训视频链接。

选择翻译和配音选项
- 选择视频源语言为培训,目标语言为捷克语。
- 选择AI捷克语配音音色(如美式、英式)或克隆原声并生成捷克语语音。
- (可选)移除原始培训字幕:
- (可选)背景音乐处理:可保留原音乐或仅保留音效。

处理与下载捷克语版视频
- AI自动完成培训到捷克语的字幕翻译、捷克语配音及音画同步。
- 可预览捷克语版作品效果,在线编辑捷克语字幕,也可批量下载捷克语版视频和SRT等文件。

获得150万创作者和企业的信赖


















为什么选择鬼手剪辑视频翻译?
鬼手剪辑提供一站式、专业级AI视频翻译和配音产品,助你的培训内容轻松走向捷克语世界。

便捷项目管理
轻松管理培训素材、字幕及捷克语译制视频。项目批量处理,高效便捷。
准确的捷克语翻译
高达99.5%准确率。专为培训到捷克语优化,经LLM校准与多Agent审校,确保捷克语译文精准地道,符合文化语境。
高质捷克语配音
多种真人般捷克语AI配音(可选美/英式口音)。高情感语音克隆复刻原声情感语调,捷克语配音自然生动。
灵活处理培训原字幕
可选无痕擦除原始培训硬字幕,提供清爽背景。支持翻译培训内嵌字幕。
智能识别培训多角色
AI自动识别培训视频多说话人,可为各角色配置或克隆捷克语音色,支持跨集识别,轻松应对短剧、访谈等多场景捷克语配音。
高效批量处理与API接口
一键批量翻译配音百个培训视频到捷克语,效率倍增。强大API接口,便捷集成至现有生产分发流程。
多种背景音处理方案
多种背景音处理选项:保留/静音原BGM,或用独有技术仅留音效,满足各场景版权与分发需求。
极致性价比
灵活的培训到捷克语翻译配音方案。免费试用核心功能,付费版自动译配低至0.2元/分钟,享专业服务。
在线便捷操作
无需安装,在线即刻翻译培训视频到捷克语。支持Windows、mac主流设备浏览器,随时随地云端处理。
相比于其他公司的优势:
翻译准、效率高和性价比高

每一分算法优化,
都是为了出品高质捷克语视频
原始培训长剧集、多角色配音的挑战与突破
一部百分钟培训长剧,多达个角色、4000句台词,为AI多角色识别和捷克语配音带来巨大挑战。传统ASR分角色技术难以精准区分众多角色,尤其在长视频中错误率(如DER错误率)显著,配音稳定性很差。鬼手剪辑采用视频、声纹、文本多模态识别技术,大幅提升长视频、多角色场景下的识别准确度和鲁棒性,更能实现培训角色身份的跨集/整部连续识别,有效解决“分不准、效率低”的行业痛点。
立即AI翻译和配音

捷克语配音连贯性和音画对齐的奥秘
为确保捷克语作品中配音连贯自然,AI在文本转语音(TTS)时,会将上下文关联的多句捷克语字幕视为完整语义单元生成流畅音频,再依每个字词的精确发音位置智能切分并生成捷克语字幕时间轴。这便是鬼手剪辑AI配音听感流畅、与各元素高度和谐统一的关键技术。而且培训到捷克语翻译常导致发音时长变化,极易引发声画脱节。鬼手剪辑的AI处理系统如经验丰富的编辑师,全自动解决此难题:它不仅可智能微调翻译后捷克语长短(可选),还能对翻译后的捷克语语音、新捷克语字幕、原视频画面及背景音乐这四大要素进行精巧分段变速与调整,实现最终的完美对齐。
立即AI翻译和配音不要让原始培训字幕成为 ROI 的障碍
培训视频翻译成捷克语,内嵌硬培训字幕常阻碍视频内容的全球化传播。真正的无痕去除,关键在于AI需深度理解并智能推测被遮挡的原始内容,而非简单模糊填充。鬼手剪辑的顶尖AI修复技术正擅长于此:它能完美恢复背景细节,即使面对复杂网格、阴影或带底色的培训字幕背景,也能自然去除且不模糊,保持视频原始画质。清晰无痕的画质为内容的二次创作、本地化及多平台分发铺平道路,有效释放视频潜力。实践证明,原始培训字幕擦除得越是无痕自然,用户的观看时长通常就越长,最终的ROI也相应更高。
立即AI翻译和配音

YouTube 创作者大爱的背景音处理
背景音乐(BGM)是视频的灵魂,但在YouTube等平台,其版权雷区不容小觑,处理不当可致视频下架乃至账号受损。需翻译的视频整体声音其实极为复杂,它交织了待翻译的人声、潜在版权风险的背景音乐、独特的场景音效以及常被ASR误译为文字的情绪声音(如哭笑声、拟声词)。鬼手剪辑自研精细声音算法,不仅能精准分离人声进行翻译和克隆配音,更能对BGM、音效与情绪声进行甄别和差异化处理。其深受YouTube创作者青睐的“保留音效和情绪声,去除音乐”选项,既巧妙规避了版权风险,又完整保留了视频的生动细节和真实情感,让内容出海更安心。
立即AI翻译和配音
让你的培训内容,无障碍触达
捷克语受众
无论您的培训内容是企业内训、产品指导还是技能课程,其原始语言(如中文或其他语种)都可能成为限制,使其难以有效传达到广阔的捷克语市场或捷克籍员工。在跨国企业扩张或本地化学习中,缺乏高质量的捷克语翻译和配音,会使得捷克语用户理解困难,严重影响学习效果、知识传递和本地化进程。因此,市场亟需专业、高效的AI解决方案,能够将各类培训内容轻松实现从培训到捷克语的无缝转化,赋能全球化学习与发展。
训练面向捷克语的AI模型:关键挑战
训练数据的限制与挑战
与全球常用语言相比,公开可用的高质量、大规模捷克语文本和语音数据集相对有限。这给从零开始训练或微调强大的AI模型带来了数据基础上的挑战,可能导致模型在覆盖面和泛化能力上存在不足。
捷克语的语言特性与复杂性
捷克语拥有复杂的语法规则,包括名词、形容词和代词的七种格变化,以及动词的多样化变位。此外,捷克语中的习惯表达、俚语和文化特定词汇丰富,这些都要求AI模型具备深度的语言理解能力,以避免直译造成的错误或生硬。
处理形态变化与语法结构
捷克语单词的形态变化繁多,同一词根可以有多种变体。训练AI模型准确识别、理解并生成这些复杂的词形变化,以及正确处理句子中词语间的语法关系(如主谓一致、修饰关系等),是技术上的一个核心难题。
语音数据的多样性与鲁棒性
捷克共和国存在不同的地区口音,人们说话的语速和风格也各异。训练能够准确识别各种口音、语速变化并有效过滤背景噪声的捷克语语音识别(ASR)模型,需要收集和处理大量多样化的真实语音数据。
捷克语文本到语音的训练
生成自然流畅、情感丰富且符合捷克语发音习惯的高品质合成语音(TTS)是一个挑战。训练这样的模型需要大量的专业录音数据,并且要能捕捉捷克语特有的语调和韵律,避免合成语音听起来机械或不自然。
跨语言模型的适配与优化
虽然大型语言模型在其他语言上取得了显著成就,但要将这些模型有效地培训到捷克语,需要进行针对性的适配和优化。这通常涉及利用有限的捷克语数据进行微调,调整模型架构或训练策略,以更好地适应捷克语的独特结构和表达方式。
模型性能的评估与提升
如何准确评估训练后的捷克语AI模型的性能是一个持续的挑战。评估需要专业的捷克语知识,设计合理的评估指标和测试集,以衡量模型在理解、生成或处理捷克语时的准确性、地道性和实用性,并据此进行迭代改进。
用AI技术克服挑战,提供一站式译制平台
已赋能许多场景的培训视频走向全球

内容创作者 - 解锁全球捷克语观众

短剧制作方 - 用捷克语短剧在APP和YouTube上拓展全球受众

跨境电商卖家 - 培训商品视频转化成捷克语

翻译服务商与本地化团队 - AI提高全语种作业效率

企业用户 - 提升捷克语市场的国际形象

在线教育机构 - 打造无障碍捷克语课程