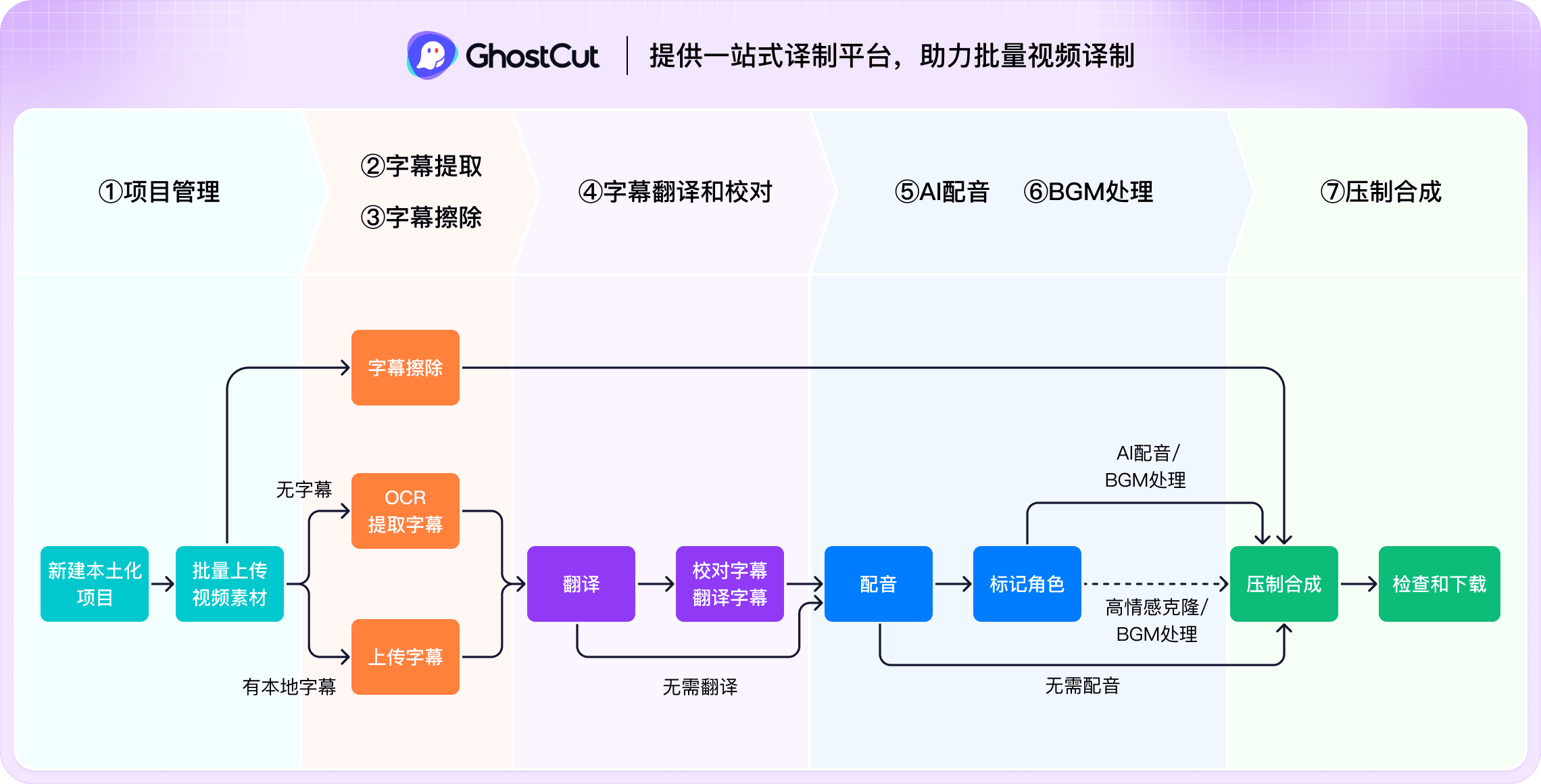
如何用AI自动将UGC视频翻译成繁体中文并配音?
使用鬼手剪辑,仅需三步,让你的UGC视频快速触达全球繁体中文观众
上传/粘贴UGC视频
- 从设备批量上传MP4, MOV等UGC视频文件。
- 或者,直接粘贴来自属于你自己的直接可访问的UGC视频链接。

选择翻译和配音选项
- 选择视频源语言为UGC,目标语言为繁体中文。
- 选择AI繁体中文配音音色(如美式、英式)或克隆原声并生成繁体中文语音。
- (可选)移除原始UGC字幕:
- (可选)背景音乐处理:可保留原音乐或仅保留音效。

处理与下载繁体中文版视频
- AI自动完成UGC到繁体中文的字幕翻译、繁体中文配音及音画同步。
- 可预览繁体中文版作品效果,在线编辑繁体中文字幕,也可批量下载繁体中文版视频和SRT等文件。

获得150万创作者和企业的信赖


















为什么选择鬼手剪辑视频翻译?
鬼手剪辑提供一站式、专业级AI视频翻译和配音产品,助你的UGC内容轻松走向繁体中文世界。

便捷项目管理
轻松管理UGC素材、字幕及繁体中文译制视频。项目批量处理,高效便捷。
准确的繁体中文翻译
高达99.5%准确率。专为UGC到繁体中文优化,经LLM校准与多Agent审校,确保繁体中文译文精准地道,符合文化语境。
高质繁体中文配音
多种真人般繁体中文AI配音(可选美/英式口音)。高情感语音克隆复刻原声情感语调,繁体中文配音自然生动。
灵活处理UGC原字幕
可选无痕擦除原始UGC硬字幕,提供清爽背景。支持翻译UGC内嵌字幕。
智能识别UGC多角色
AI自动识别UGC视频多说话人,可为各角色配置或克隆繁体中文音色,支持跨集识别,轻松应对短剧、访谈等多场景繁体中文配音。
高效批量处理与API接口
一键批量翻译配音百个UGC视频到繁体中文,效率倍增。强大API接口,便捷集成至现有生产分发流程。
多种背景音处理方案
多种背景音处理选项:保留/静音原BGM,或用独有技术仅留音效,满足各场景版权与分发需求。
极致性价比
灵活的UGC到繁体中文翻译配音方案。免费试用核心功能,付费版自动译配低至0.2元/分钟,享专业服务。
在线便捷操作
无需安装,在线即刻翻译UGC视频到繁体中文。支持Windows、mac主流设备浏览器,随时随地云端处理。
相比于其他公司的优势:
翻译准、效率高和性价比高

每一分算法优化,
都是为了出品高质繁体中文视频
原始UGC长剧集、多角色配音的挑战与突破
一部百分钟UGC长剧,多达个角色、4000句台词,为AI多角色识别和繁体中文配音带来巨大挑战。传统ASR分角色技术难以精准区分众多角色,尤其在长视频中错误率(如DER错误率)显著,配音稳定性很差。鬼手剪辑采用视频、声纹、文本多模态识别技术,大幅提升长视频、多角色场景下的识别准确度和鲁棒性,更能实现UGC角色身份的跨集/整部连续识别,有效解决“分不准、效率低”的行业痛点。
立即AI翻译和配音

繁体中文配音连贯性和音画对齐的奥秘
为确保繁体中文作品中配音连贯自然,AI在文本转语音(TTS)时,会将上下文关联的多句繁体中文字幕视为完整语义单元生成流畅音频,再依每个字词的精确发音位置智能切分并生成繁体中文字幕时间轴。这便是鬼手剪辑AI配音听感流畅、与各元素高度和谐统一的关键技术。而且UGC到繁体中文翻译常导致发音时长变化,极易引发声画脱节。鬼手剪辑的AI处理系统如经验丰富的编辑师,全自动解决此难题:它不仅可智能微调翻译后繁体中文长短(可选),还能对翻译后的繁体中文语音、新繁体中文字幕、原视频画面及背景音乐这四大要素进行精巧分段变速与调整,实现最终的完美对齐。
立即AI翻译和配音不要让原始UGC字幕成为 ROI 的障碍
UGC视频翻译成繁体中文,内嵌硬UGC字幕常阻碍视频内容的全球化传播。真正的无痕去除,关键在于AI需深度理解并智能推测被遮挡的原始内容,而非简单模糊填充。鬼手剪辑的顶尖AI修复技术正擅长于此:它能完美恢复背景细节,即使面对复杂网格、阴影或带底色的UGC字幕背景,也能自然去除且不模糊,保持视频原始画质。清晰无痕的画质为内容的二次创作、本地化及多平台分发铺平道路,有效释放视频潜力。实践证明,原始UGC字幕擦除得越是无痕自然,用户的观看时长通常就越长,最终的ROI也相应更高。
立即AI翻译和配音

YouTube 创作者大爱的背景音处理
背景音乐(BGM)是视频的灵魂,但在YouTube等平台,其版权雷区不容小觑,处理不当可致视频下架乃至账号受损。需翻译的视频整体声音其实极为复杂,它交织了待翻译的人声、潜在版权风险的背景音乐、独特的场景音效以及常被ASR误译为文字的情绪声音(如哭笑声、拟声词)。鬼手剪辑自研精细声音算法,不仅能精准分离人声进行翻译和克隆配音,更能对BGM、音效与情绪声进行甄别和差异化处理。其深受YouTube创作者青睐的“保留音效和情绪声,去除音乐”选项,既巧妙规避了版权风险,又完整保留了视频的生动细节和真实情感,让内容出海更安心。
立即AI翻译和配音
你的UGC内容,值得被
繁体中文观众看见
许多精彩的UGC内容,无论其原始语言是简体中文或其他,都可能因语言隔阂而难以触及庞大的繁体中文观众群体。例如,那些充满创意的短视频、引人入胜的系列短剧、实用的生活Vlog或专业的教学内容,若缺乏高质量的繁体中文翻译与配音,便会使繁体中文用户在理解上遭遇障碍,这不仅严重影响了观看体验,也削弱了内容的互动率与传播潜力。鉴于此,市场对一套专业、高效的AI视频翻译与配音解决方案的需求日益迫切,旨在将各类UGC内容轻松、准确地译制成繁体中文。
UGC内容繁体化:挑战与考量
硬字幕与混合文字障碍
许多UGC视频内嵌简体中文硬字幕,或混杂网络特殊用语。将其准确无误地转换为符合规范的繁体中文,且不影响观看体验,是基础挑战。
文化、用语与习惯差异
UGC中常见的简体中文网络流行语、地域性表达和文化梗,在繁体中文语境下可能难以理解或接受。如何进行在地化转换,使其自然融入繁体中文使用者的日常表达,是核心难点。
词汇及句式适配挑战
简体与繁体中文不仅是字符差异,更存在大量词汇用法和惯用句式的不同(例如,某些科技、生活类词汇)。将UGC的文本精准翻译为台湾或香港习惯使用的繁体中文表达,需要深入的语言功底。
原文风格与语调保持
UGC内容常带有鲜明的个人风格、情感和非正式语调。在转换为繁体中文时,如何在保证准确性的同时,最大限度地保留原文的生动性和感染力,避免生硬感。
自动识别与转换局限
依赖AI工具进行UGC文本识别和简繁转换,可能因原文质量(口音、语速)、非标准用语、或模型训练偏向,导致转换不准确,尤其是对新兴网络词汇和多义词的处理。
高品质在地化标准
理想的UGC繁体化过程应实现:准确捕获原始文本(包括非标准语)- 深入理解内容进行文化和词汇的在地化转换(符合目标地区的语言习惯)- 生成自然、流畅且忠于原文风格的繁体中文文本。
用AI技术克服挑战,提供一站式译制平台
已赋能许多场景的UGC视频走向全球

内容创作者 - 解锁全球繁体中文观众

短剧制作方 - 用繁体中文短剧在APP和YouTube上拓展全球受众

跨境电商卖家 - UGC商品视频转化成繁体中文

翻译服务商与本地化团队 - AI提高全语种作业效率

企业用户 - 提升繁体中文市场的国际形象

在线教育机构 - 打造无障碍繁体中文课程